
티스토리 뷰
Reactive Programming
- 데이터가 통지되면 이에 반응하여 데이터를 처리 하는 방식의 프로그래밍 모델. 즉, 프로그램에서 필요한 데이터를 직접 가지고와서 처리하는 방식(pull)이 아닌 데이터를 받은 시점에 처리하는 방식(push).
- 이를 구현하기 위해 데이터를 만들어내는
생산자와 이를 소비하게 되는소비자로 역할을 나눠 처리하는 프로세스를 가지게 된다. - 소비자와 생산자의 역할이 분리되어 있으므로, 생산자는 데이터를 생산하여 전달하는 역할까지 수행하며, 소비자는 데이터를 받아서 처리하는 역할만을 수행한다. 즉, 생산자와 소비자는 각각의 역할만 충실하게 수행하면 되고, 반대편에서 어떤 처리를 하는지에 대해서는 관심 밖의 일이다.
이처럼, 역할이 분리됨에 따라 쉽게 비동기 구현이 가능
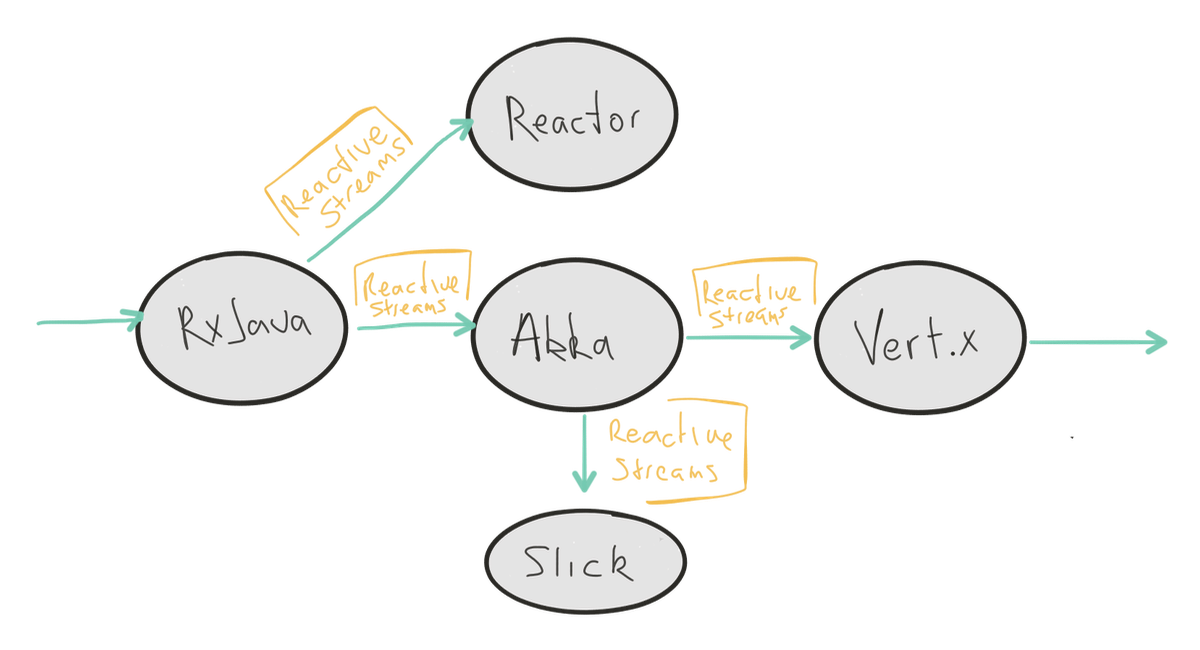
Reactive Stream
데이터 스트림을비동기로 처리 할 수 있는 공통 메커니즘/인터페이스.- Reactive Stream은 인터페이스만 제공하고 상세 구현은 각 라이브러리/프레임워크에서 책임을 가져간다.
구현체
데이터스트림
- Collection과 같이 이미 생성한 데이터를 포함하여
앞으로 생성할 데이터혹은발생 가능성이 있는 데이터까지 포함하는 개념. - 키보드 혹은 마우스 같은 UI상에서의 이벤트가 발생 했을 때, 해당 이벤트가 발생하는 시점의 데이터까지 포함하는 개념으로 볼 수 있다.
- 데이터스트림의 소스 종류들은?
- SQL 쿼리들
- GUI 이벤트
- HTTP 기반 서비스
- TCP 소켓
- 파일 시스템
- Kafka같은 메시지 큐들
- 기타 등등
구성
- Reactive Stream은 Publisher와 Subscriber로 구성되며, Subscriber가 Publisher를 구독하면 Publisher가 통보하는 데이터를 받을 수 있음
- 구독(subscribe)가 발생하면 이에 대한 Subscription이 생성된다.
- Subscriber가 Publisher를 구독하지 않으면 이후 단계는 진행되지 않는다.
- onComplete, onError와 같이, 확정 Action이 발생하면 소비자에게 통보한다.
- Subscriber는 Publisher에게 받을 데이터 개수를 요청 할 수 있으며, 요청 받은 Publisher는 다시 데이터를 생산하여 Subscriber에게 전달(onNext)한다.
- 받을 데이터 개수를 요청하는 것은 생산자측의 처리 속도와 소비자측의 처리 속도가 다를 수 있기 때문에, 이를 제어 할 수 있는 적절한 수단이 필요하기 때문
표준 인터페이스
| 인터페이스 | 설명 |
|---|---|
| Publisher | 데이터 생성/통보 |
| Subscriber | 데이터 처리 |
| Subscription | 데이터 요청/ 구독 해지 가능 |
| Processor | Publisher & Subscriber의 역할을 모두 가지고 있음 |
위 표준 인터페이스를 보면 알 수 있듯이, 분명하게 역할 분리가 되어 있음을 알 수 있다. 이는 곧 처리 단위 별로 개별 책임을 가져 갈 수 있음을 뜻함.
규칙
Reactive Stream은 인터페이스를 통하여 데이터를 통지하는 구조이며, Reactive Stream에서 정해놓은 규약을 충분하게 지켜야 구조가 제대로 동작한다.
- 구독 시작 통지(onSubscribe)는 구독에서 한 번만 발생
- 데이터 통지는 순차적으로 이뤄진다.
- null을 통지하지 않는다.
- Publisher는 처리 완료(onComplete) 혹은 에러(onError)를 통하여 종료한다.
[주의] 같은 인스턴스를 활용하여 구독(subscribe)를 할 경우, Publisher/Subscriber의 내부 상태를 초기화하지 않으면 의도하지 않은 결과로 이어질 수 있다. 왜냐하면, onComplete 혹은 onError의 통지가 이뤄진 이후 시점에는 Publisher는 처리가 끝마친 것으로 판단하기 때문이다.
RxJava,Kotlin에서 꼭 알아야 할 구조는?
생산자/소비자/구독
| ReactiveStream 지원 유/무 | 생산자 | 소비자 | 관계 |
|---|---|---|---|
| O | Flowable | Subscriber | Subscription |
| X | Observable | Observer | Disposable |
지원 유무의 가장 큰 차이점은
배압(Backpressure)의 적용 유무, 배압이 적용되어 있지 않기 때문에, 별도로 소비자측에서는 데이터를 요청하지 않음. 배압 외에는 처리 모델은 거의 똑같다.
연산자
map, flatMap 및 filter 등과 같이 기존 Stream을 다루거나 함수형 라이브러리에서 제공해주는 연산자를 비슷하게 제공해주고 있음. 연산자별로 생성되는 Flowable/Observable의 성격이 상이한 부분이 존재하며, 또한 실행순서에 영향을 주는 연산자도 존재함.
순차 처리의 예
Flowable.just(1,2,3,4,5,6,7,8,9,10) .filter { it % 2 == 0 } .map { it * 100 } .subscribe { println("${Thread.currentThread().name}, data: $it") }
[결과]
main, data: 200
main, data: 400
main, data: 600
main, data: 800
main, data: 1000
순차 처리가 안되는 예
Flowable.just("A", "B", "C") .flatMap { Flowable.just(it).delay(1000L, TimeUnit.MILLISECONDS) }.subscribe { println("${Thread.currentThread().name}: $it") }
[결과]
RxComputationThreadPool-3: C
RxComputationThreadPool-1: A
RxComputationThreadPool-1: B
비동기 처리
생산자와 소비자는 별도의 지정이 없을 경우, 메인스레드 혹은 실행 스레드에서 순차 처리 됨.
하지만 시간 관련 Flowable/Observable 생성자의 경우, 별도의 스레드에서 실행이 되는 경우도 있음. 비동기 처리를 지정해야 할 경우 생산자 측(subscribeOn())과 소비자 측(observeOn())에 스레드 스캐줄러를 지정하면 되며, 스캐쥴러(Schedulers)의 종류는 io, computation 등이 있다.
외부 자원에 대한 참조는?
생산자/소비자는 여러 스레드에서 실행이 될 수 있기 때문에, 공유 자원에 대해서 동기화 작업을 반드시 수행해줘야 한다. 이런 동기화를 피하는 가장 좋은 방법은 아래와 같다.
- 순수 함수(함수형 인터페이스)의 사용
- 외부 자원 참조 X
- 함수 단위로 코드를 전개하여 처리 안정성을 확보
- 불변 객체의 사용, 큰 오버헤드가 존재하지 않으면 객체는 복사를 하여 사용하는 것이 좋다.
여러 개의 생산자/소비자가 존재 할 경우는
merge등의 연산자를 통하여 해당 생산자/소비자를 실행하는 스레드가 공유 자원에 대해 동기화하여 접근 할 수 있도록 할 수 있다.
공유 자원에 대한 잘못된 접근의 예
아래의 2개의 생산자/소비자의 구조에서 2개의 소비자 모두 변수 num에 접근하여 값을 수정하고 있는데, 이는 각각의 소비자에서 스레드에 대한 적절한 동기화 없이 접근하는 안티패턴의 가장 좋은 예라고 할 수 있다.
var num = 0 Flowable.range(1, 100_000) .subscribeOn(Schedulers.computation()) .observeOn(Schedulers.computation()) .subscribe( { ++num }, { println("에러=$it") }, { println("counter.get()= $num") } ) Flowable.range(1, 100_000) .subscribeOn(Schedulers.computation()) .observeOn(Schedulers.computation()) .subscribe( { ++num }, { println("에러=$it") }, { println("counter.get()= $num") } )
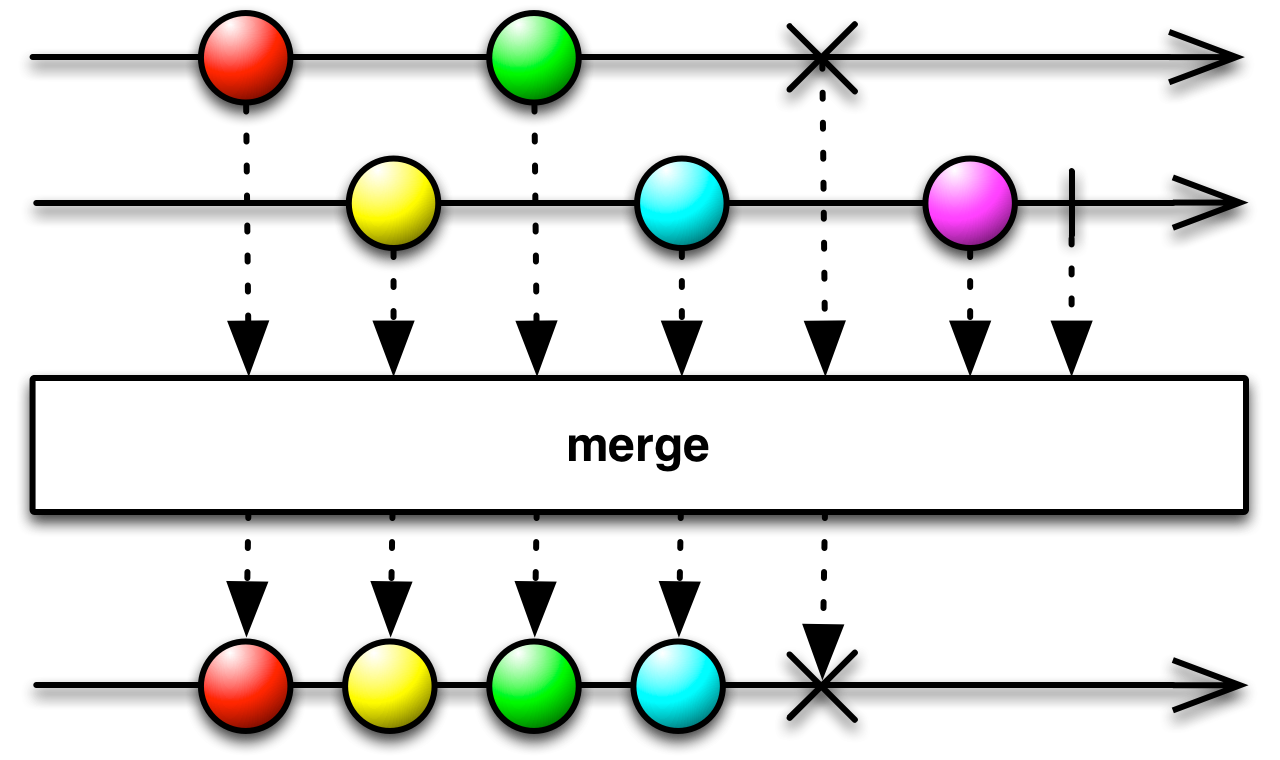
merge 연산자를 사용한 예
위에서 보았던 안티패턴을 Rx에서는 스레드에 대한 동기화 처리를 진행해주는 merge 연산자를 사용하여 해결이 가능하다. 여러 생산자에서 발행하는 데이터의 타임라인을 하나로 만들어주며, 발행하는 순서를 아래의 그림과 같이 시간순 혹은 실행순으로 만들 수 있다.
[요약] 여러 Observable의 출력을 결합하여 단일 Observable처럼 작동하도록 할 수 있다.
var num = 0 val source1 = Flowable.range(1, 100_000) .subscribeOn(Schedulers.computation()) .observeOn(Schedulers.computation()) val source2 = Flowable.range(1, 100_000) .subscribeOn(Schedulers.computation()) .observeOn(Schedulers.computation()) Flowable .merge(source1, source2) .subscribe( { ++num }, { println("에러=$it") }, { println("counter.get()= $num") } )
Flowable vs Observable 어떤걸 써야 하는거지?
Flowable
- 대량 데이터를 처리 할 경우
- 네트워크 통신/파일 등 IO를 처리 할 경우
Observable
- GUI 이벤트
- 소량의 데이터를 처리 할 경우
- 자바의 Stream을 대신하여 사용할 경우
대량의 데이터와 더불어 IO를 처리 해야 할 경우에는 Flowable을 사용하여 적절한 배압 정책을 적용하는 것이 유리하다. 반면에 GUI의 이벤트 처리 혹은 소량의 데이터를 처리 할 경우 배압이 없는 Observable을 사용하는 것이 유리하다고 한다. Observable은 배압 기능이 없는 만큼 Flowable에 비하여 오버헤드가 적은 것이 특징이다.
배압 기능을 사용하면, 쏟아지는 데이터 대한 적절한 제어 뿐만 아니라 에러 처리도 할 수 있다. 물론, 다루는 데이터의 성격에 따라 달라질 수 있는 부분이지만 생산자와 소비자간의 처리 속도 차이에 따라 발생하는 데이터 유실에 대한 부분도 반드시 고려해서 배압 정책을 적용한 코드를 작성해야 한다.
'Programing > Kotlin' 카테고리의 다른 글
| Kotlin-In-Action 9장 제네릭스 (0) | 2021.07.27 |
|---|---|
| Alternatives to JPA (1) | 2019.05.01 |
| 코틀린의 코루틴(`Coroutine`)을 어떻게 이해할것인가? (0) | 2019.03.02 |
| Kotlin With Spring Boot (0) | 2019.03.02 |
- Total
- Today
- Yesterday
- HTTP
- maven
- Squelize.js
- WebFlux
- pm2
- cluster
- HttpClient
- Sublime Text 3
- 스프링
- RestTemplate
- http method
- Spring Boot
- Sublime Text 2
- Express.js
- jade
- ecma
- Handlebars
- EJS
- Kotlin
- springboot
- implicit prototype chain
- tomcat
- Spring MVC
- node.js
- Prototype
- Package Control
- SideBarEnhancements
- package.js
- Til
- Spring
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |